Nothing everything is commented:
root@DietPi:~# crontab -l
# Edit this file to introduce tasks to be run by cron.
#
# Each task to run has to be defined through a single line
# indicating with different fields when the task will be run
# and what command to run for the task
#
# To define the time you can provide concrete values for
# minute (m), hour (h), day of month (dom), month (mon),
# and day of week (dow) or use '*' in these fields (for 'any').
#
# Notice that tasks will be started based on the cron's system
# daemon's notion of time and timezones.
#
# Output of the crontab jobs (including errors) is sent through
# email to the user the crontab file belongs to (unless redirected).
#
# For example, you can run a backup of all your user accounts
# at 5 a.m every week with:
# 0 5 * * 1 tar -zcf /var/backups/home.tgz /home/
#
# For more information see the manual pages of crontab(5) and cron(8)
#
# m h dom mon dow command
root@DietPi:~#
On cron.d there ares this files:
certbot:
0 */12 * * * root test -x /usr/bin/certbot -a \! -d /run/systemd/system && perl -e 'sleep int(rand(43200))' && certbot -q renew --no-random-sleep-on-renew
e2scrub_all
30 3 * * 0 root test -e /run/systemd/system || SERVICE_MODE=1 /usr/lib/aarch64-linux-gnu/e2fsprogs/e2scrub_all_cron
10 3 * * * root test -e /run/systemd/system || SERVICE_MODE=1 /sbin/e2scrub_all -A -r
php
09,39 * * * * root [ -x /usr/lib/php/sessionclean ] && if [ ! -d /run/systemd/system ]; then /usr/lib/php/sessionclean; fi
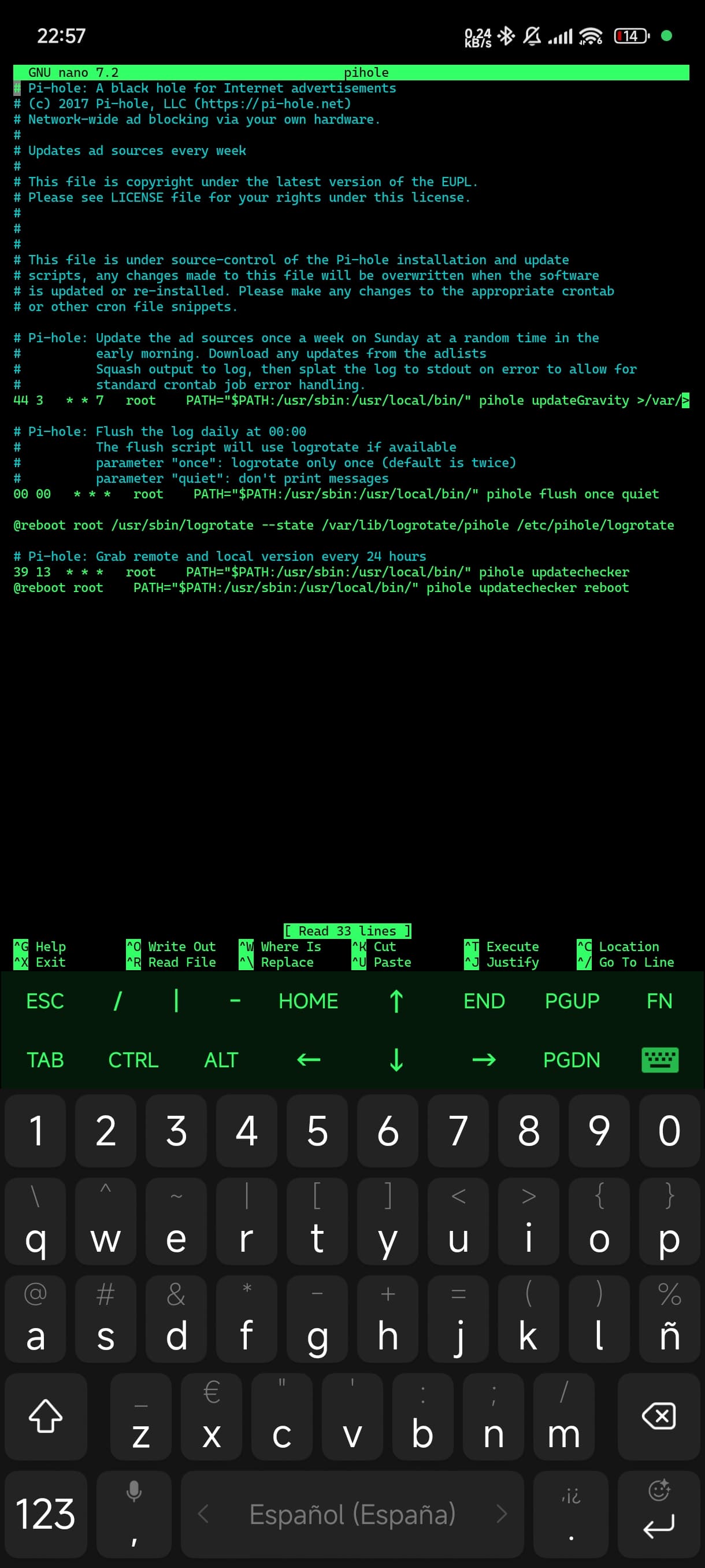
pihole
44 3 * * 7 root PATH="$PATH:/usr/sbin:/usr/local/bin/" pihole updateGravity >/var/log/pihole/pihole_updateGravity.log || cat /var/log/pihole/pihole_updateGravity.log
00 00 * * * root PATH="$PATH:/usr/sbin:/usr/local/bin/" pihole flush once quiet
39 13 * * * root PATH="$PATH:/usr/sbin:/usr/local/bin/" pihole updatechecker
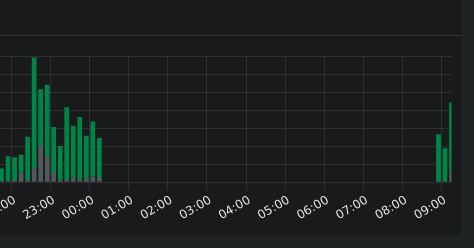
I was going to list every cron on every file of every folder on cron folder, and wathching pihole file I see some reboots, for example:
Pi-hole: Grab remote and local version every 24 hours
39 13 * * * root PATH="$PATH:/usr/sbin:/usr/local/bin/" pihole updatechecker
@reboot root PATH="$PATH:/usr/sbin:/usr/local/bin/" pihole updatechecker reboot
That last reboor means that is going to reboot my Odroid?? because if the answer is yes, that’s the problem, because odroid hc4 does not reboot, Ihad to power off and back on.
Some work around? it’s that reboot needed?