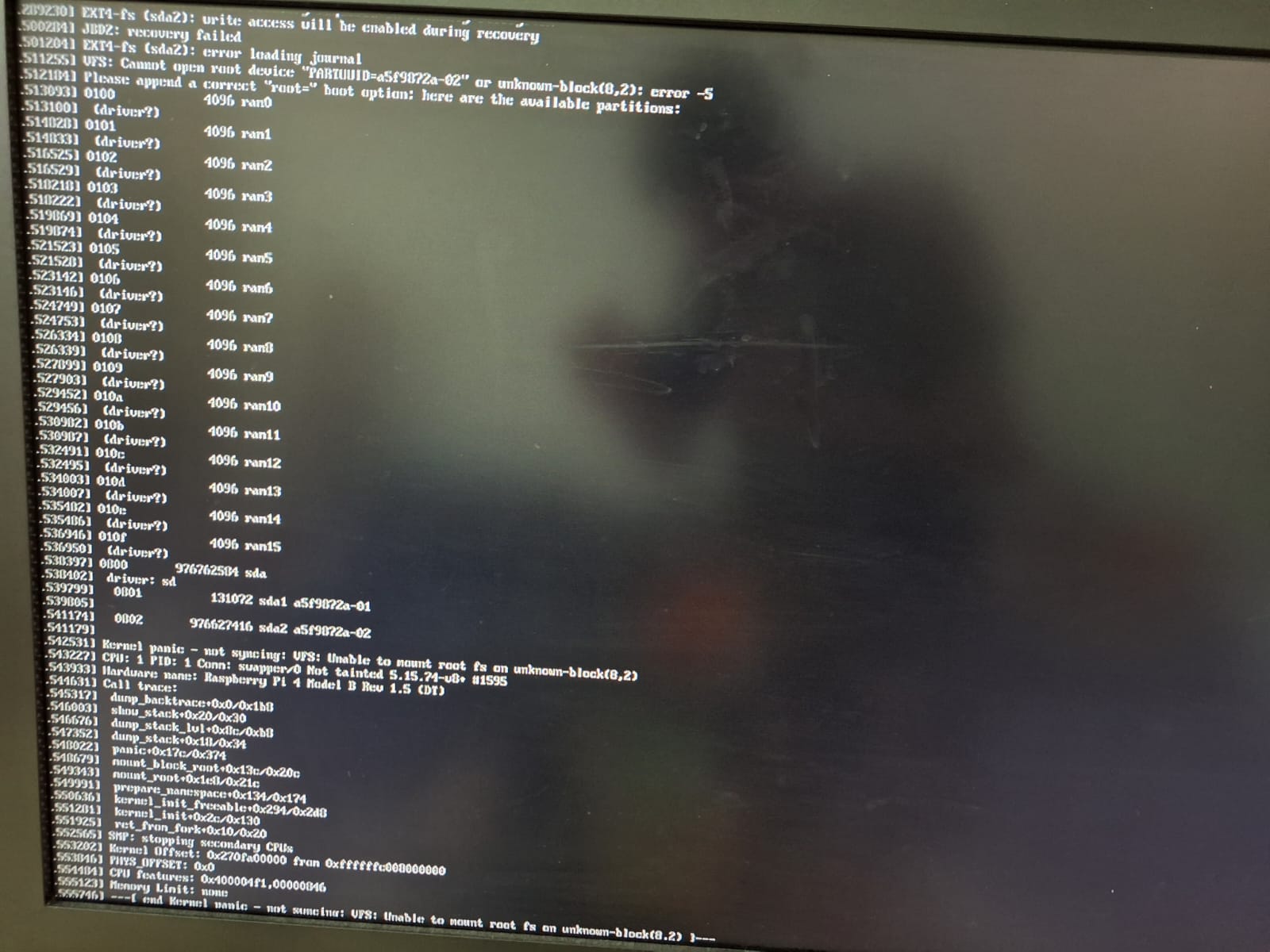
I can’t pinpoint a specific point when it stopped being able to boot, but I don’t think it was right after an update or else I would have noticed.
For the record I tried connecting the SSD to my laptop (windows) and I could see a small partition with some dietpi files but not the main partition since it’s ext4.
What can I do? Preferably without flashing the SSD since I have some things that are not backed up. Also, if the small partition showed up on my laptop does it mean the SSD is fine?
Windows is not able to read ext4 at all. Therefore, it is not displayed. There are ways to make ext4 partitions available, but they require Windows 11 and WSL2
It looks like you have data corruption on your SSD. How is the SSD supplied with power? With its own power supply or just via the RPI4’s USB port? The RPi4 is not designed to power HDD or SSD via the USB port. This is a limitation of the SBC and we strongly recommend using an external power supply or powered USB hub.
What you could try is to flash a new SD card with a new image and boot from it. Then connect your SSD (do not mount the SSD) and run a file system check.
The SSD was supplied with power through the PI itself which I didn’t know was an issue. I will order an enclosure with its own power supply for the future.
In the meantime I was unable to mount the main partition using WSL2 (I am on an appropriate windows 11 version), ran into the similar errors.
The disk was attached but failed to mount: Input/output error.
For more details, run 'dmesg' inside WSL2.
To detach the disk, run 'wsl.exe --unmount \\.\PHYSICALDRIVE1'.
I encountered roughly the same problem: moving DIetPi on my RPi4b from SDCard to external USB enclosure. I downloaded the latest RPi 4 image, wrote the image to the USB device (I am on LinuxMint, and I used “Make Bootable USB stick” option from the file explorer: this turned out to be a mistake). Unmounted the USB device, plugged into the RPi, and rebooted without the SDCard.
All went fine; DietPi boots and installs. However, upon first reboot I saw nearly the same BIOS screen output as yours: can’t mount the second partition, do not see an ext4 filesystem.
So the issue is that you need to write the entire disk image properly, I saw two proper partitions and then unused space when I used “Open with…” and then selected “Disk Image Writer” which uses Disks. This worked properly upon install and first reboot!
How is your USB hard drive supplied with power? Does it have its own power supply or is it only powered via the USB port of the RPi4? Because the USB ports of the RPi4 are not technically designed to power things larger than a pen stick. Especially at peak times or high loads, there can be problems with the power supply and this can then lead to data corruption or data loss. We therefore recommend that you always use a separate power supply unit for the external disks or a powered USB hub.
About 24 hours later, I agree with you now!; it is the best recommendation!
A few reboots of the RPi with only the USB drive attached (only powered by RPi through USB) and it has been fine.
However, I proceeded to boot off the SDcard with the USB drive attached, rsync’d most of /mnt/dietpi_userdata from SDcard to the USB mount, shutdown, and removed the SDcard. Upon power up, I get a different error, basically bad blocks on the ext4 partition, but the boot process proceeds during a filesystem check and repair. After a reboot or two, I’ve got a working system again.
So I agree, at this point, this is likely a power issue when I have combined storage media!
I’ll try it out for a few more days, I don’t mind the experiment because I can always fall back to my SDcard! I may try to connect a Kill-A-Watt later to see if I can measure the total system power draw between storage options. It would be nice to know if there’s any way to determine power draw from Debian.
It is not about the total power consumption of the SBC. It’s more about the maximum power that the USB ports can provide. If I’m not mistaken, it’s even divided between them.
So I booted dietpi from an sd card and connected my SSD (this time with an enclosure that supplies power externally).
What can I try now?
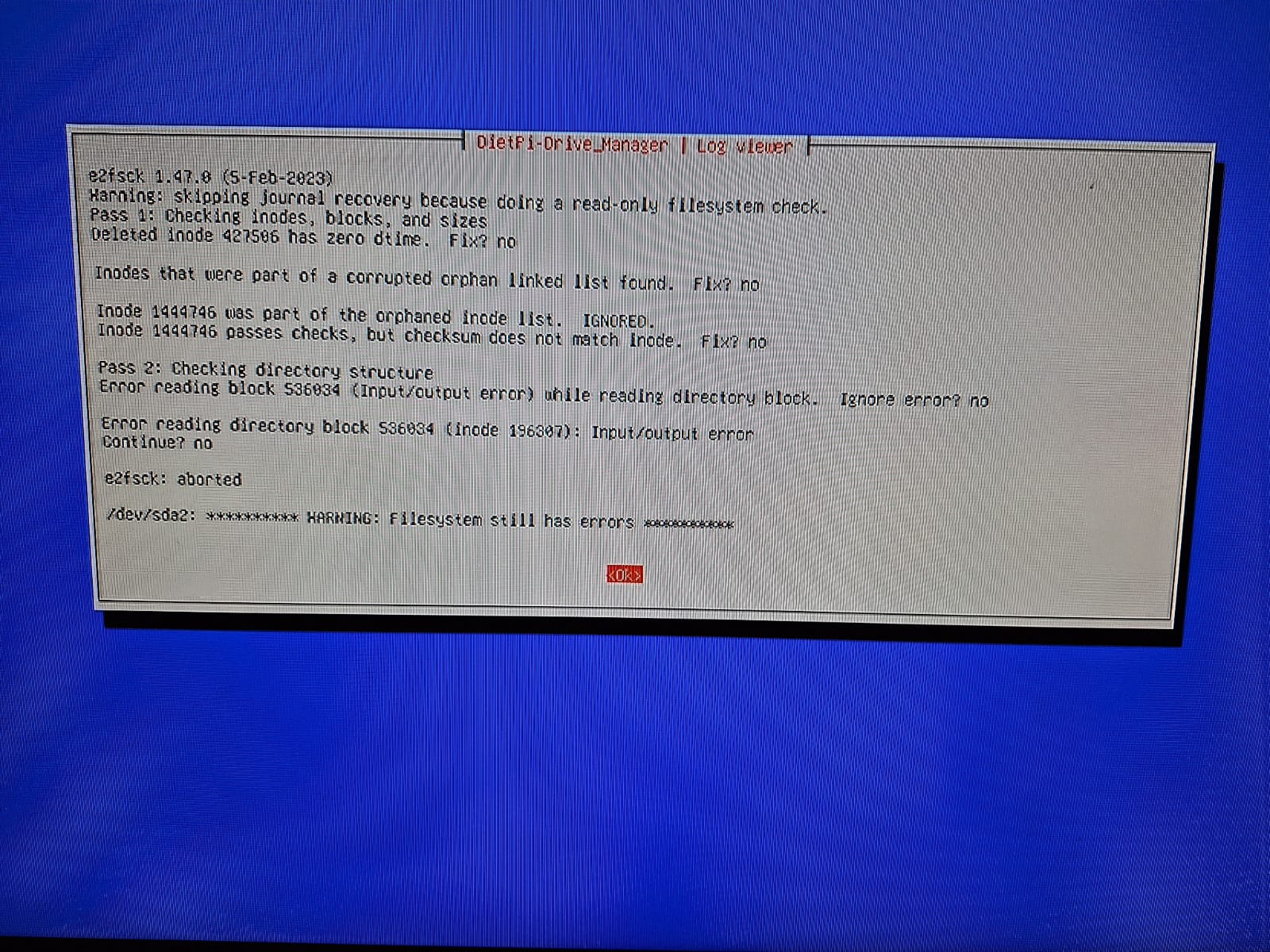
So far I went to dietpi-drive_manager and ran a “check & repair”. It’s currently running. Seems like it doesn’t do anything. A terminal window opened at the bottom after pressing “ok” for the check, but it doesn’t further display anything, still shows the “ok window”. Not sure if something is stuck or if this is intended behavior and it’s just a long process.
For anyone wondering it does just appear stuck but is actually running, let it run for a bit.
Couldn’t repair with fsck so I decided to just reflash and start fresh. I tried copying a large directory on the new install of dietpi but twice now that it fails and the entire system becomes read only until I restart the PI.
Quick google lead me to believe something is wrong with the drive so I ran a smartctl check (smartctl -t long /dev/sda) but it seems to have passed just fine?
smartctl -a /dev/sda
Results:
=== START OF INFORMATION SECTION ===
Model Family: WD Blue / Red / Green SSDs
Device Model: WDC WDS100T2B0A-00SM50
Serial Number: 22013B802470
LU WWN Device Id: 5 001b44 8b78b8363
Firmware Version: 415020WD
User Capacity: 1,000,204,886,016 bytes [1.00 TB]
Sector Size: 512 bytes logical/physical
Rotation Rate: Solid State Device
Form Factor: 2.5 inches
TRIM Command: Available, deterministic, zeroed
Device is: In smartctl database 7.3/5319
ATA Version is: ACS-4 T13/BSR INCITS 529 revision 5
SATA Version is: SATA 3.3, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Fri Aug 18 13:28:35 2023 BST
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x00) Offline data collection activity
was never started.
Auto Offline Data Collection: Disabled.
Self-test execution status: ( 0) The previous self-test routine completed
without error or no self-test has ever
been run.
Total time to complete Offline
data collection: ( 0) seconds.
Offline data collection
capabilities: (0x11) SMART execute Offline immediate.
No Auto Offline data collection support.
Suspend Offline collection upon new
command.
No Offline surface scan supported.
Self-test supported.
No Conveyance Self-test supported.
No Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 2) minutes.
Extended self-test routine
recommended polling time: ( 10) minutes.
SMART Attributes Data Structure revision number: 4
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
5 Reallocated_Sector_Ct 0x0032 100 100 --- Old_age Always - 0
9 Power_On_Hours 0x0032 100 100 --- Old_age Always - 4772
12 Power_Cycle_Count 0x0032 100 100 --- Old_age Always - 100
165 Block_Erase_Count 0x0032 100 100 --- Old_age Always - 571435780815
166 Minimum_PE_Cycles_TLC 0x0032 100 100 --- Old_age Always - 7
167 Max_Bad_Blocks_per_Die 0x0032 100 100 --- Old_age Always - 102
168 Maximum_PE_Cycles_TLC 0x0032 100 100 --- Old_age Always - 63
169 Total_Bad_Blocks 0x0032 100 100 --- Old_age Always - 633
170 Grown_Bad_Blocks 0x0032 100 100 --- Old_age Always - 0
171 Program_Fail_Count 0x0032 100 100 --- Old_age Always - 0
172 Erase_Fail_Count 0x0032 100 100 --- Old_age Always - 0
173 Average_PE_Cycles_TLC 0x0032 100 100 --- Old_age Always - 28
174 Unexpected_Power_Loss 0x0032 100 100 --- Old_age Always - 72
184 End-to-End_Error 0x0032 100 100 --- Old_age Always - 0
187 Reported_Uncorrect 0x0032 100 100 --- Old_age Always - 0
188 Command_Timeout 0x0032 100 100 --- Old_age Always - 947
194 Temperature_Celsius 0x0022 061 060 --- Old_age Always - 39 (Min/Max 26/60)
199 UDMA_CRC_Error_Count 0x0032 100 100 --- Old_age Always - 0
230 Media_Wearout_Indicator 0x0032 005 005 --- Old_age Always - 0x053502500535
232 Available_Reservd_Space 0x0033 100 100 004 Pre-fail Always - 100
233 NAND_GB_Written_TLC 0x0032 100 100 --- Old_age Always - 29666
234 NAND_GB_Written_SLC 0x0032 100 100 --- Old_age Always - 41126
241 Host_Writes_GiB 0x0030 253 253 --- Old_age Offline - 12020
242 Host_Reads_GiB 0x0030 253 253 --- Old_age Offline - 50492
244 Temp_Throttle_Status 0x0032 000 100 --- Old_age Always - 0
SMART Error Log Version: 1
No Errors Logged
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Extended offline Completed without error 00% 4772 -
Selective Self-tests/Logging not supported
I am a bit confused then. Is the drive OK or does it have a problem?
If it’s ok why does the system keep locking up as readonly when doing something as simple as copying a folder.
PS: fsck -a also shows no errors: /dev/sda2: clean, 367760/61046784 files, 10085954/244157622 blocks
Before we try other things, the closest idea would be to try another drive and/or cable/enclosure.
You flashed new and still got problems, despite smartctl and fsck find nothing, which is very odd.
Yeah., I suppose it’s possible the drive was initially corrupted due to me supplying it power through the pi (even though it was running like that for a year), and that now the issues I am experiencing are due to the enclosure/cable being defective somehow.
Assuming I can get my hand on another SSD, which I am not sure I can at the moment, what’s a good way to check if the error is still occurring (which would suggest the enclosure is bad), since smartctl and fsck report fine. Just copy the same folder again?
Do you think I should try to test the SSD with the old enclosure that requires supplying power through the PI, to figure out if the new enclosure is defective? Or is it a bad idea since undersupplying it with power could cause more issues?
No I wouldn’t try the unpowered enclosure.
You don’t need to use a SSD, just test the adapter with another hard drive to figure out if your SSD has some damage.
Please run fsck with forced check, otherwise it skips an actual check as long as no dirty bit is set:
fsck -f /dev/sda2
And just to rule some things out, try to replace the USB cable, switch to another USB port and (as suggested by Jappe) replace the SSD with any other SATA drive, respectively.
I did end up reflashing and trying it (before your comment in my defense hah). I don’t want to speak too soon but so far with this enclosure it hasn’t failed yet (whereas with the other enclosure I never get this far over 3 different installations and many tries with each installation).
And as I was writing this comment it failed again, the system turned read only.
By the way restarting just now the system turned on but was very slow/slugish.
I turned off the PI and booted from the SD card so I could run fsck against the SSD.
fsck -f -n /dev/sda2
Results:
fsck from util-linux 2.38.1
e2fsck 1.47.0 (5-Feb-2023)
Pass 1: Checking inodes, blocks, and sizes
Inode 1078470 extent tree (at level 1) could be narrower. Optimize? no
Inode 1078510 extent tree (at level 2) could be narrower. Optimize? no
Inode 1078817 extent tree (at level 2) could be narrower. Optimize? no
Inode 1079093 extent tree (at level 2) could be narrower. Optimize? no
Inode 1079095 extent tree (at level 2) could be narrower. Optimize? no
Inode 1080934 extent tree (at level 2) could be narrower. Optimize? no
Inode 1320756 extent tree (at level 2) could be narrower. Optimize? no
Inode 2237441 extent tree (at level 2) could be narrower. Optimize? no
Inode 2237523 extent tree (at level 2) could be narrower. Optimize? no
Inode 2237527 extent tree (at level 2) could be narrower. Optimize? no
Inode 2237536 extent tree (at level 2) could be narrower. Optimize? no
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Pass 5: Checking group summary information
/dev/sda2: 657151/61046784 files (0.5% non-contiguous), 18433284/244157622 blocks
I am no expert on parsing said results but it seems like nothing is critical on there? This just keeps getting confusing. Unfortunately, I don’t have another drive. I could buy another SSD (which is what I am trying to avoid by attempting to figure out if the SSD is the issue).
I am going to switch to another USB port and try again. But it’s a pain in the ass to troubleshoot since I don’t know what triggers the system to become read only. Like just now when I though the enclosure was the issue but turns out it still failed eventually. Any suggestion for a stress test that could trigger that?
I even ran a disk benchmark from drive manager when first starting with the underpowered enclosure and it seemed to pass just fine.
For the record booting again from the SSD (still the same USB port) and it seems it’s no longer slow/slugish, so perhaps it’s just the first boot after crashing to read only (I also observed this slowness after the system crashing with the properly power supplied enclosure)
It is an ext4 filesystem option to automatically remount read-only in case of I/O errors, to prevent actual/further filesystem corruption as good as possible. But I am also not sure why this happens in your case even if doing a drive benchmark does not cause an issue.
One thing, out of interest, what does this show?
hdparm -B 255 /dev/sda2
Usually SSDs do not support APM (Advanced Power Management) anyway, but in case this does does, the above command disables it. It should not cause issues anyway, but let’s just rule out everything.
Btw, does the kernel show any other error?
dmesg -l 0,1,2,3
And is/was the RPi throttled as of too high temperature or low voltage?
When booting from SSD. The first at best shortly after boot, so see whether unexpectedly things remain stable, the other two diagnose commands are most valuable in case after the drive mounted read-only.