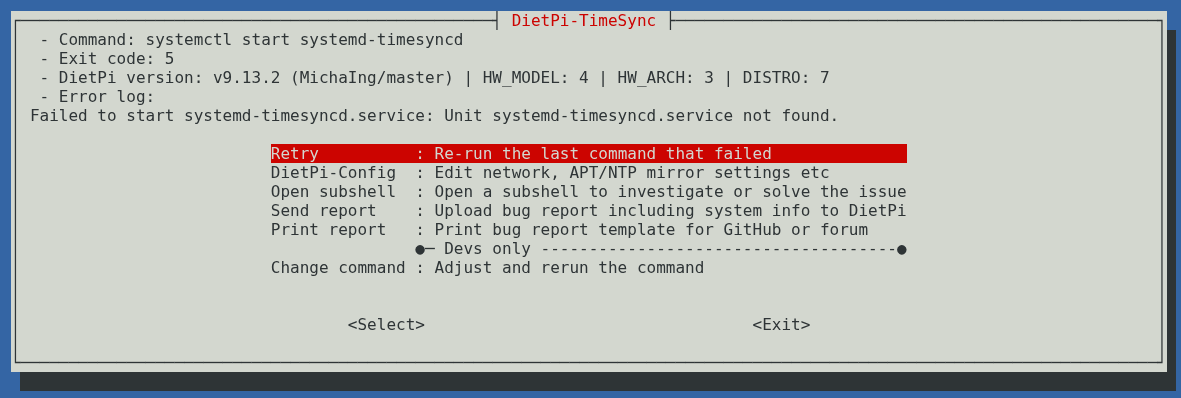
I’m running two Raspberry Pi devices on DietPi, both as dedicated Pi-hole and Nginx reverse proxy. I’m attempting to update both to DietPi version 9.14.2, but I keep encountering the following error:
Failed to start systemd-timesyncd.service: Unit systemd-timesyncd.service not found.
I’ve tried switching to different NTP servers, including various mirrors and local devices, but the error persists. I’ve also confirmed that chrony is not installed on either device.
Additionally, I’ve noticed some odd behavior with Pi-hole since switching from Tailscale to Netbird for my network. I’m not sure if this is related to the update issue, but I thought it’s worth mentioning. When I was using Tailscale, I didn’t experience any problems with either Pi-hole or DietPi updates.
Has anyone encountered this systemd-timesyncd.service error during a DietPi update, or have any insights into potential conflicts with Netbird? Any suggestions for troubleshooting or resolving this would be greatly appreciated!
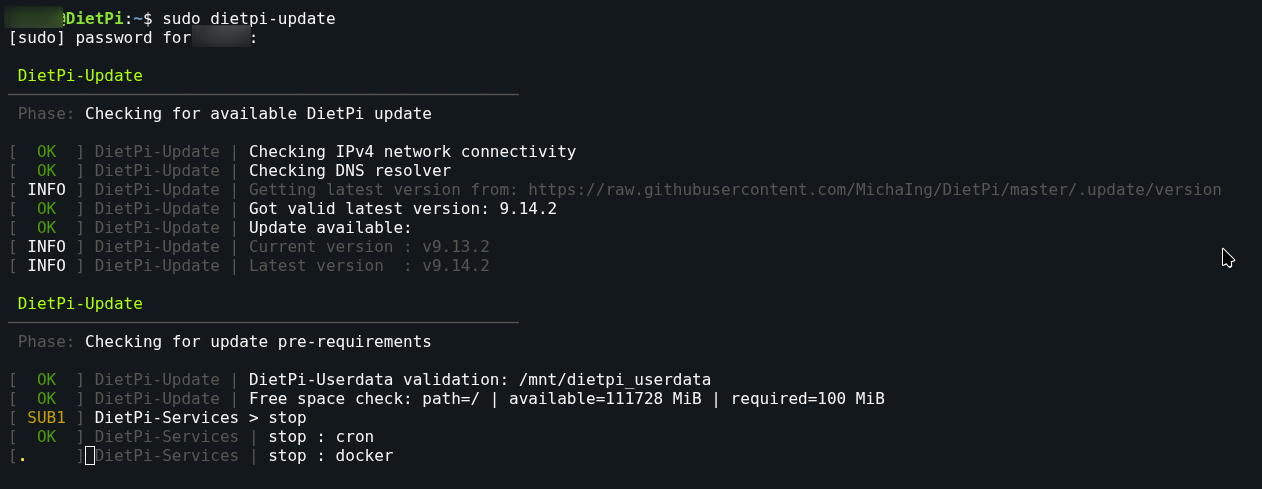
I ran apt install systemd-timesyncd and now the error doesn’t show anymore, but when applying the update the ssh output stops and nothing happens. I restart the ssh session and the update clearly didn’t apply, as it’s still telling me I need to do it.
It not even reached the update phase as its still trying to stop services. Obviously it has issue to stop Docker. Probably a container taking some time. Can you check on a 2nd ssh session docker service logs? As well how long did you wait?
That was not the problem. I was ssh’ing into dietpi using nexterm and for some reason dietpi’s update locks up nexterm which I’ve never seen before. Used konsole terminal by KDE and the update went through.
As Joulinar said, the DietPi update did not even start. What is happening there is:
systemctl stop docker
You can run this command and observe the same. It stops all/most Docker containers, but gives them overall, AFAIK, 90 seconds by default, not sure whether Docker or containers can influence this timeout. It is hence one container which takes very long to stop, maybe hangs the system on a lower level. If a new SSH session cannot be opened once this happened, you can open one before trying to stop Docker, open e.g. htop there, then stop Docker wth above command in the other session, and see which process is causing much CPU load, respectively which process within a container (by default htop visualizes this via tree view) remains, where they should have been all stopped gracefully in reasonable time.